How to Accurately Use Percentages for Project Tracking
Mike Shoemake has been a successful software developer for 20 years, building quality applications and high-performing development teams.

software project estimation
Pixabay
Introduction
Estimation is just hard. Unfortunately, it's also very necessary. Companies use estimates to project out release schedules, make commitments to their customers, decide whether a proposed feature is worth implementing, track teams' velocity, and prioritize the work effectively. Executives often want to know when a feature or deliverable will be ready for production. After all, software development is not a trivial investment. Without estimates, how would the project manager make an assessment? If humans could predict the future accurately, people wouldn't win at horse races 2% of the time. Estimation is the great conundrum. It's essential and necessary for companies to ask their people to do the impossible: predict the future.
First, let's review some popular estimation methods (in case you missed some of the excitement). Then we can look at what this means to us and our projects.
The Fortune Teller Model
This model requires almost no effort to produce an estimate. Estimators think for a bit about what needs to be done to implement and test a feature, then they throw out a number. It sounds a lot like "... (long pause) ... Ummmmm … 6 weeks." Then everyone nods and we move on. They could spend quite a while on the front end talking through what they know of the requirements (which is probably not the complete picture). This careful analysis makes their estimate feel more reliable. At the end of the project, there's always an accepted rationale for why the estimate was so far off from reality. There are always unforeseen circumstances that can serve as a scapegoat. It often doesn't occur to anyone that the model is severely flawed.
So how can we make this process better? I know! We can use the Decomposition Technique (ie. divide and conquer). This approach assumes that you know the complete scope of the feature or project on the front end. Every feature is broken down into bite-sized chunks. Each chunk is estimated (fortune-teller style), then we add them up to get an overall feature/project estimate. This is certainly a more complicated approach, but it seems better for two reasons:
- Smaller chunks of work tend to be easier to estimate reliably.
- While there is still the opportunity for error (+/- some amount), there is an assumption that the errors will cancel each other out when you add it all up and you'll get a more reliable overall estimate.
The fundamental flaw with this approach is that individual contributors (the people who actually do the work) universally underestimate. They are still significantly better than those above and around them, but that's not a high bar. This doesn't seem like the case because we've all seen cases where developers surprised themselves by accomplishing something ahead of schedule. But this is a single data point, not a trend. People do actually win occasionally at the casino; spend money at a casino every day for a year and you will have less money than you started with. If you track estimates vs. actuals for a year or two, you'll discover that the estimates do fall short of reality. While many business people are absolutely sure that developers are lazily padding their estimates and using the extra time to "gold-plate" or check their stocks, the data shows otherwise. The "canceling out" strategy doesn't work.
So, now what? Let's ditch the fortune-teller model and switch to a size-based approach. It turns out that, while humans are pretty awful at estimating completion time, we're actually pretty good at saying how big something is. We're especially good at comparative sizing ("it's bigger than that, but smaller than that over there"). If we think in terms of size or complexity rather than time, our brains process it more reliably. Then we can take the size values and calculate the actual number of hours for the project based on a nifty magic formula! And that's when the popular function points model enters the scene (stage left).
Function Points Analysis (FPA)
For function point analysis, we need to identify five types of things in our application: external inputs, external outputs, external queries, external interface files, and internal logical files (don't worry too much about definitions; you can research those later). Each example of those (a function) has a complexity associated with it (low, average, or high). We use the table below to figure out how many points each function gets assigned.
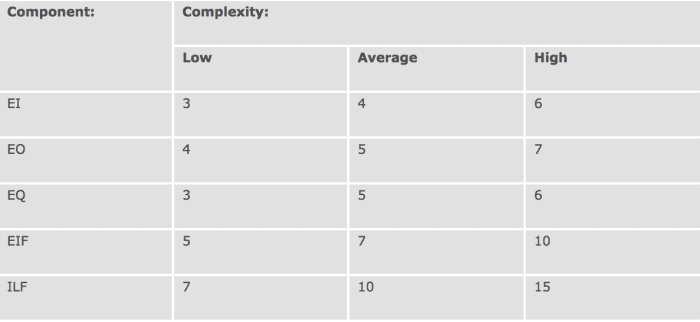
Now if we add up the points for all of our functions we might get a number like 457 function points for our project. Then we just need a formula to figure out the number of hours… Based on our last project, our "delivery rate" was 15 function points per person per month. That's roughly 30 person months worth of work, which should take a little over two and a half months for my team of 12. Ta-da!
This certainly is more complex than our previous model. In fact, there are four key areas of complexity to recognize.
- The five component types aren't necessarily intuitive, and it's easy to forget to put something in the list or assign it to the wrong bucket.
- The table used to actually generate the function points contains magic numbers that would require a lot of effort to validate. Are these numbers calibrated properly to generate reliable estimates for my teams?
- The delivery rate (a critical piece of the puzzle) is calculated based on your team's productivity. How often do we need to calculate a new number? There's actually very little guidance on this.
- What constitutes low, average, or high complexity? How do we define that so everyone understands it? Isn't getting that right critical to the accuracy of our calculations?
There are several moving parts in this very simple example, and we haven't even discussed more complicated complexity models and the other data that can come into play (ex.cost rate, support rate, defect density, etc.). More moving parts means more opportunities for errors to occur. Are we making estimation too complicated now? We're not paying developers to devote a lot of time to estimation. I can't sell an estimate to my customers. I need working software. Is there anything else out there?
Read More From Toughnickel
Going Agile
Now let's look briefly at agile scrum (just enough to do a comparison). As stated earlier, humans are terrible at estimating time, and are pretty good at comparative sizing. Here are a couple terms to understand:
- A sprint - a time boxed period of time (usually two weeks).
- User story - a discrete piece of work, preferably small enough to be done by one person in a sprint. This is the thing we're estimating.
The most popular strategy is using a fibonacci sequence (0, 1, 2, 3, 5, 8, 13) for estimates. It's not linear--as you go up the scale the size of the gaps increase. The key is that the gaps should be wide enough that there is no reason to argue over insignificant differences. Once you get above 3, the difference between 4 and 5 or 7 and 8 are so negligible that it's pointless to spend time hashing out which one it is. A base-2 sequence would also work (0, 1, 2, 4, 8, 16, etc.).
"But wait, this is just a number. What does it mean? How many hours is a point?" Points are not intended to correlate directly to hours, because if they did teams would be tempted to go back to estimating in hours and then converting that to points somehow. As discussed earlier, the accuracy of our estimates comes from comparative sizing and not estimating the number of hours something will take. If you give the team the ability to think in terms of hours, you're compromising your ability to estimate accurately.
Let's say you started with a calibration exercise. Pull your team into a room and walk them through a list of 10-12 user stories. Pick one that's small but not the smallest and do that one first. Review it and announce that this story is a "3". You're not asking. You're telling. Then move on to the next story. "If that was a 3, what is this one?" Now the team is sizing stories relative to other stories. Eventually, they'll have a pretty good idea what constitutes a "1", a "2", etc. They're not estimating. Time doesn't matter. They're sizing stories, relative to other stories that already have a number. You can then put example stories for each number in the sequence in a document called a ruler. They can use that as a reference if they aren't sure what a "5" is.
Now here's the key. The magic sauce that makes this work is "velocity" (the number of points a team can complete in a sprint averaged across 3-4 sprints). Let's say your sprint is two weeks and your team of 8 people has an average velocity of 35 points. You're getting 35 points done in 640 hours of work (8 x 80 hours). If we figure out that a feature is going to take about 100 points worth of work start to finish then I know that's about 6 weeks of work and ~1900 hours. The team gets very good at consistently sizing stories, and you leverage that to do your project planning. This calculation works because the duration is consistent from sprint to sprint.
To do long term high-level planning, you can ask your leads to break down high level features into interim one-liner stories and put point values on them. There will be a degree of accuracy lost, but you're leveraging the model they already understand. A more accurate path would be relative sizing at the feature level. "This feature is bigger than that 40 point feature, smaller than that 120 point feature over there, and slightly bigger than the 65 point feature we just did." Stories are grouped into "epics". If each feature is an epic, at the end you'll know how many points it took to complete that feature. Keep a history of that and you can use it for your release planning.
Conclusion
There are plenty of methodologies in use today. Each has pros and cons. Somehow we need to figure out how to maximize the accuracy of our estimates so we can make good decisions. That doesn't mean our estimates have to be accurate. They just need to be accurate enough that they're useful. If you don't understand estimation, you might assume that the estimates weren't accurate because the team didn't do a good job. They didn't estimate correctly, or they didn't execute on the project correctly. Beatings will continue until estimates improve. But estimates should never be used as a commitment. It's a best guess based on the limited information we have today. When new information pops up, we have to allow estimates to be revisited. Anything else is expecting the impossible, which is a problem with leadership (not with the team).
Scrum's approach is much simpler than what we see in function points analysis. And I would say it's much more trustworthy than magic tables with magic numbers. It gets the most bang for the buck (minimal effort with a reasonably high degree of accuracy). From an effort perspective, it doesn't create a heavy-weight process for the teams to understand and use. The estimation piece of agile can actually happen very quickly once everyone understands the details of the work being estimated. It's certainly better than pulling numbers out of thin air. Leveraging velocity does something very important: it brings historical data into the calculation. Every sprint, you recalculate your velocity. This is critical, because over time throughput changes. Teams that use FPA might derive their delivery rate from their previous project, which in some cases was several months ago. A lot has probably changed since then. My suggestion is for you to explore Agile and really put effort into understanding story points and velocity. Don't fall back on estimating in hours just because that's what you understand. I believe you will thank yourself later.
Quick Poll
This article is accurate and true to the best of the author's knowledge. Content is for informational or entertainment purposes only and does not substitute for personal counsel or professional advice in business, financial, legal, or technical matters.
Mike Shoemake (author) from Cumming, GA on April 26, 2017:
Much appreciated. Thanks for stopping by!
jouzif414 on April 22, 2017:
magnificence
How to Accurately Use Percentages for Project Tracking
Source: https://toughnickel.com/business/Estimating-Software-Projects-Effectively
0 Response to "How to Accurately Use Percentages for Project Tracking"
Post a Comment